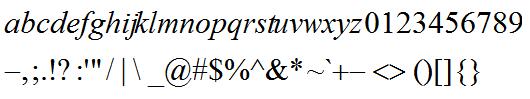Facebook推出深度学习引擎DeepText,挑战谷歌智能系统!作者:2016-06-02朱焕、闻菲 新智元来源:2016-06-02朱焕、闻菲 新智元 【北京大数据研究院导读】 6月1日,Facebook的研发团队基于深度学习方法,推出了文本理解引擎DeepText。目前该引擎可以处理超过20种语言,使用多个深度神经网络构架,结合监督、无监督学习,实现从零开始,在字词和字符水平上进行学习。官方称此项技术可以接近人类的准确度、以每秒数千篇文本的速度快速理解文本内容。 摘要 本文表明,我们可以使用时间卷积网络(ConvNet)把深度学习运用于文本理解,从字符水平的输入开始,直到获得抽象文本概念。我们把ConvNet运用于包括本体分类、情感分析和文本分类在内的多个大规模数据集。我们发现,时间ConvNet可以在不具有对词、短语、句子和任何其他语法或语义结构的知识的情况下很好地理解文本。证据表明我们的模型既可用于英语,也可用于汉语。 1.引言 在本文中我们表明,可以在不具有关于词、短语、句子或任何语法、语义结构知识的情况下利用深度学习系统来进行文本理解。我们将时间ConvNets运用于多个大规模文本理解任务,在这些任务中,输入是经过quantize的字符,而输出是文本的抽象属性。在下面的两种意义上,我们的方法是一种“从零开始学习”的方法。 1.ConvNet不需要词的知识——它可以直接处理字符。这就使得基于词特征的提取器(如Collobert等的LookupTable)或Mikolov等的word2vec变得不必要了。所有先前的工作都从词开始,而非从字符开始;这些基于词的工作因为具有高维度,很难运用卷积层处理。 2.ConvNet不需要关于语法或语义结构的知识——它可以直接针对高级目标进行推理。过去人们假设,对高级文本理解而言,结构预测和语言模型是必要的。ConvNets的工作方式证明这一假设是错的。 ConvNet在计算视觉领域的成功是让我们采用这一方法的原因之一。在计算视觉领域的这些成功通常涉及到,用端到端的ConvNet模型来从原始像素输入中学习分层表示。与此类似地,假设通过从原始字符中进行训练,时间ConvNet能够学习到对词、短语和句子的分层表示,从而能理解文本。 2.ConvNet模型设计 在本部分,我们介绍了用于文本理解的ConvNet的设计。该设计是模块化的,通过反向传递来获得梯度、进行优化。
2.1 核心模块 我们模型的主要部分是一个时间卷积模块,该模块计算输入和输出之间的一维卷积。假设我们有一个离散输入函数g(x)∈[1,l]→R。那么f(x)与g(x)之间具有步幅d的卷积为h(y)∈[1,[(l-k)/d]+1]→R,它被定义为:
其中c=k-d+1是偏移常量。正如视觉领域的传统卷积网络一样,该模型由建立在输入集gi(x)和输出集hj(y)之上的核函数fij(x)(i= 1,2,...,m;j=1,2,...,n) 的集合来参数化。我们把每个gi(或 hj)称为输入(或输出)帧,而将 m(或 n) 称为输入(或输出)帧大小。通过对gi(x)和fij(x)之间的i个卷积进行加和,就能获得输出hj(y)。
一个能帮助我们训练更深度的模型的核心模块,是时间max-pooling方法。它与在计算视觉中使用的空间max-pooling模块相同,所不同的仅仅是它是一维的。给定一个离散输入函数g(x)∈[1,l]→R,g(x)的max-pooling 函数 h(y)∈[1,[(l-k)/d]+] 可被定义为:
其中c=k-d+1是偏移常量。
我们在模型中使用的非线性方法是rectifier或thresholding函数h(x)=max{0,x},这使得我们的卷积层类似于修正线性单元(ReLU)。在每个卷积或线性模块之后,我们都会使用该函数。训练模型时使用的算法是随机梯度下降(SGD),其minibatch大小为128,momentum为0.9,起始步长为0.01,而每经过三个epoch,步长就会减半,直至第十次。上述训练方法和参数适用于我们所有的模型。我们使用 Torch7来进行实现。 2.2 字符数字化 我们的模型接受一系列的编码字符作为输入。编码方法是,从被输入的语言中得到一个大小为m的字母表,然后使用1-of-m编码方法对每个字符进行数字化。之后,字符序列被转化为一个由大小为m的向量组成的具有固定长度l的序列。任何超过长度l的字符都被忽略;空白字符也包含在字母表内,而任何不在字母表内的字符都被数字化为all-zero向量。受长短时记忆神经网络(LSTM)的工作方法的启发,我们以反向顺序对字符进行数字化。通过这种方式,对字符的最晚近的读取总是被放置在输出起点的附近,这样,那些全连接层就很容易与最晚近的记忆建立相关性联系。由此,我们的模型的输入是一个长度为l的帧的集合,而帧的大小是字母表大小m。
我们在所有模型中使用的字母表包括70个字符,其中包括26个英文字符,10个数字、换行符和33个其他字符。
在将输入传递给模型之前,没有进行任何归一化(normalization)。这是因为输入本身已相当稀疏,包含了许多0值。我们的模型可以通过这种简单的数字化方法进行学习,并未发生问题。
2.3 模型设计 我们设计了两个ConvNet,一个大的和一个小的。它们都具有9个层,其中有6个卷积层和3个全连接层,各层具有不同数量的隐藏单元和帧大小。 2.4 用同义词典进行数据增强
我们做实验用一个英语同义词典来进行数据增强。该词典来自LibreOffice项目中的mytheas组件。 为了对给定文本进行同义词替换,我们需要回答两个问题:文本中的哪些词需要被替换,同义词典中的哪个同义词应该被用来替换。为了回答第一个问题,我们从给定文本中提取了所有可被替换的词,并从中随机抽取r个来进行替换。采用数字r的概率符合几何分布P[r]~p^r。而给定需被替换的词后,采用字典中第s个同义词的概率则符合另一个几何分布P[s]~q^s。由此,当一个词的同义词离其常见意义越来越远时,其概率也会变得越来越小。
值得注意的是,使用我们的大规模数据集训练的模型几乎不需要进行数据增强,因为它们在泛化错误方面的表现已经很好了。不过我们仍将使用这种新的数据增强技术来报告我们的结果,并令p=0.5,q=0.5。
2.5 比较模型 由于我们是从零开始建立了多个大规模数据集,并不存在已发表文献供我们与其他方法进行比较。因此,我们也使用以前的bag-of-words模型和通过word2vec 实现的bag-of-centroids模型建立了两个标准模型,以供比较。
3. 数据与结果 在本部分,我们展示了从各数据集中获得的结果。不幸的是,尽管文本理解研究已进行了几十年,尚不存在足够大或标记质量足够高的开放数据集供我们研究。因此,我们提供了几个大规模数据集,希望能像图像识别在ImageNet开放后取得成功一样,文本理解也能在开放了大规模数据集后走向成功。 3.1.DBpedia Ontology Classification 3.2.Amazon Review Sentiment Analysis 3.3.Yahoo! Answers Topic Classification 3.4.News Categorization in English 3.5.News Categorization in Chinese
4.结论与展望 本文中我们第一次证明了,ConvNet可被应用于从零开始的文本理解任务。也就是说,ConvNets不需要任何关于语言的语法或语义结构知识,就能产生好的文本理解测评结果。
我们还可以想想,如何将无监督学习用于从零开始学习语言模型。之前的嵌入性方法(Collobert et al.,2011b) (Mikolov et al.,2013b) (Le&Mikolov,2014) 已表明,对输入中错漏掉的词或其他模式进行预测,这是很有用的。我们希望能将这些迁移学习和无监督学习技术应用于我们的模型。
同样值得注意的是,自然语言本质上是时间序列。因此,将我们的方法进行扩展,就可以用它去处理时间序列数据。在这种应用中,分层特征提取机制或许能够带来新的进步,超越目前广泛使用的循环模型和回归模型。
本文中我们只将ConvNet应用于对语义或情感意义的文本理解。我们还可以把它扩展到分块(chunking)、命名实体识别(NER)和词性标注等其他传统NLP任务中去。
最后,我们的模型还可以用于数学公式、逻辑表达式或程序语言等符号系统中的学习。 DeepText技术关键 综上,DeepText使用了包括卷积神经网络和循环神经网络在内的多个深度神经网络构架,是无监督学习和监督学习的结合,可以在词水平和字符水平上进行学习。 DeepText训练模型时使用了FBLearner Flow和Torch。DeepText的两大特色是深度学习和词嵌入方法。 传统NLP方法中,词被转换成计算机算法可以学习的形式,例如,单词brother会被转化成4598这样的整数ID。与传统NLP方法不同,DeepText使用了词嵌入技术。该技术能保留词之间的语义关系。使用这种技术,机器可以发现"brother"和"bro"这两个词的词嵌入在词嵌入空间中彼此邻近。这样,词嵌入技术便能够捕捉词语更深层的语义学含义,也能够帮助机器理解不同语言之间的同义现象。例如,在词嵌入空间中,英语的"happy birthday"与西班牙语的同义短语"feliz cumpleanos"距离非常接近。
简单说,DeepText使用的深度学习方法有几个优点:
▷能够教会机器去理解俚语和单词歧义。例如,当一个人说“我喜欢黑莓”的时候,深度学习能帮助机器辨别用户说的黑莓是指水果还是指黑莓手机。 ▷处理复杂的规模化问题和语言问题时,传统的NLP技术效果不太好,而深度学习可以让机器更好地处理多语言文本,并更高效地处理标记数据。 ▷可以直接从没有进行过预处理的文本中进行学习,从而降低对语言知识的依赖性。 ▷在只拥有小的标记数据集时也能进行有效学习。 下一步,DeepText研发团队将让DeepText: ▷能更好地理解用户的兴趣,从而能为用户提供与其兴趣更匹配的内容。 ▷具有把文本和图片内容结合起来理解的能力。 ▷发展诸如双向循环神经网络 (BRNN) 等新型深度神经网络。 Facebook会成为下一个谷歌? 在聊天机器人或者说虚拟智能助理市场,Facebook的M是谷歌、亚马逊、微软、IBM等几大巨头中唯一走文字输入路线的。因此,Facebook推出深度学习文字搜索引擎,是自然的结果,这也与Facebook的十年发展规划相符——以深度学习为代表的人工智能技术将成为其未来三大支柱之一,以此拓展业务,完善生态系统。
Facebook的目标是理解用户的一切。未来,如果DeepText与Facebook的虚拟智能助理M整合,Facebook就能更好地理解用户及其需求,并且更好地连接商家和消费者——这不仅仅会为Facebook增加广告收入,还会在其平台上形成一个生态闭环。
用户在Facebook上花费的时间越多,留下的信息量也就越大,Facebook的搜索引擎也会变得更加智能。试想,当你在 Facebook与朋友约好见面,接下来打车、订餐、购物都能在Facebook完成,而且所有你感兴趣并且想知道的新闻、资讯、好友消息都能在这个平台上找到,你还会退出Facebook吗?
那么,接下来很容易想到一个问题:
我们还需要谷歌吗?
Facebook有社交网络固有的局限,那就是用户都活在一个个“圈子”里。而当人想知道圈外的消息时——虽然有研究称,平均通过7个人就能把世界上任何两个人联系起来——但再怎么“万物互联”,有时候还是自己动手更加方便。
何况谷歌还有Google Assistant。 转载自:2016-06-02朱焕、闻菲 新智元
文章分类:
行业资讯
|