北 京 大 数 据 研 究 院
BEIJING INSTITUTE OF BIG DATA RESEARCH

鄂维南:探寻人工智能最本质问题,希望做到源头创新本文转载自 DeepTech深科技知乎专栏文章:《探寻人工智能最本质问题,希望真正做到源头创新》
随着 5G 时代的带来,非结构化数据将爆发式地增长,也给数据探索带来了一系列的困难。
墨奇科技正是围绕这一背景,突破性地从底层开始通过源头性的创新来解决。他们提出了新型数据框架,将不同类型的非结构的数据从基础的表示层转化为统一的二维表示,从而让非结构化数据可以如结构化的关系型数据般在系统中被存储、快速的调取和搜索查询。通过将这类数据转化成“传统的关系型数据”,能够很好地解决“一个 AI 对应一个功能”的问题,实现 AI 泛化,以及数据的共享化,最终做到“大一统”。 未来,相关企业或许不用关心数据形式和数据利用性能的问题,只专注于为用户提供最出色的体验。而这些都得利于墨奇科技提出的创新数据框架。 墨奇科技无监督基于上述的创新数据框架,从源头出发成功地攻克了这一人工智能领域非常棘手的问题,即解决了无监督自学习框架对于数据的依赖,并将之称为小样本无监督自学习。他能够凭借较少的样本训练,来实现精确度极高的无监督自学习框架。 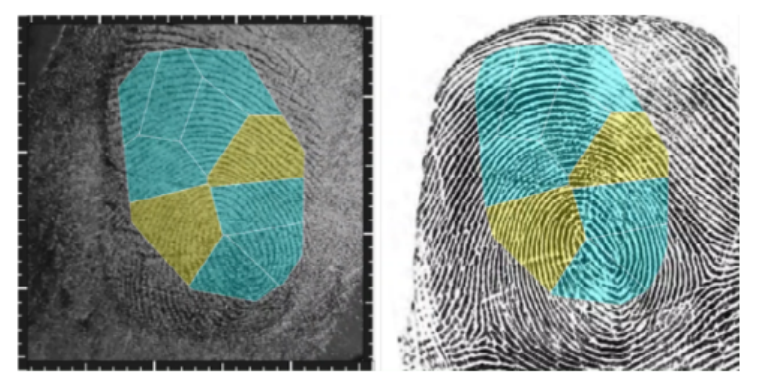 墨奇科技为了解决这一问题,提出了覆盖存储和搜索的异构分布式系统以及高精准度的秒级比对、识别与搜索功能。 2. 在提取出特征后,将特征均匀的分配到图像搜索服务器上,并在内存中建立索引。 3. 面对需要搜索图片时,先会图片经过特征提取服务器提取出特征,然后将这些特征发送至图像搜索服务器进行检索。 4. 检索主要分为 GPU 检索和 CPU 检索两个步骤:GPU 检索能够快速地筛选候选图片,然后再用 CPU 进行精确检索。 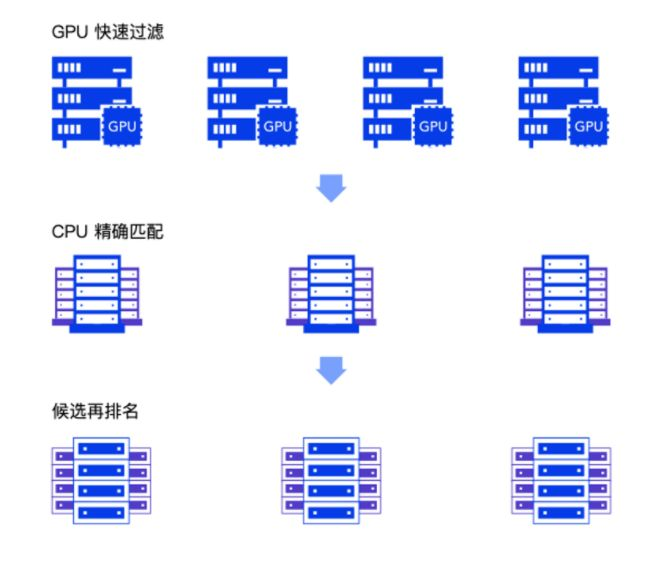 墨奇科技 CEO 及联合创始人邰骋曾说过:“我们和大部分的创业公司都不太一样,我们甚至从创立墨奇前,关心的就是很长远的问题,也就是人工智能的机理。” |

